


A quick but deep incident report for operators and allocators. The aim is clarity and practical steps, not alarm.
What happened
A bug in the Reth execution client stalled nodes that depended on it. Engineers published guidance and patches. The network continued to finalize because the client share was limited and other clients kept producing and validating blocks.
Incident timeline
Early alerts flag stalls on a subset of nodes.
Teams confirm the bug in state root computation on specific Reth versions.
Workarounds and patches ship.
Node operators resync and the network continues with normal finality.
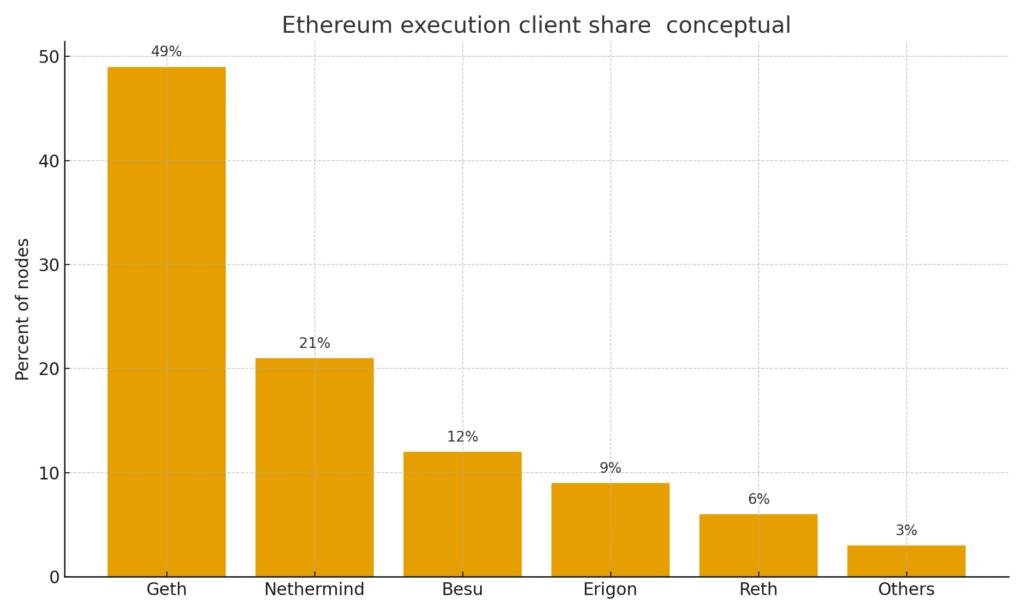
Figure 1. Bar chart of Ethereum execution client share with Geth dominant and Reth a small percentage, illustrating diversity.
Triage checklist for operators
Identify version and sync status.
If on an affected version, follow vendor steps to resync or downgrade.
Check monitoring for missed slots or peer drops.
Confirm slashing protection and key safety before restarting.
Document the change so future audits can verify actions.
What to improve before the next incident
Balance client share so that no single execution client controls a supermajority.
Stage updates across availability windows instead of all at once.
Run shadow nodes on an alternate client for quick failover.
Publish a clear runbook for incident response.
Final read
A glitch in one client did not stop the chain. That is the point of mixed clients. Keep the split healthy, keep your runbooks current, and practice the handoffs.
Related Posts
Venus Protocol incident Phishing loss pause and a defense playbook for DeFi teams
Solv and Chainlink enable real time collateral verification for SolvBTC Dossier and blueprint
September market setup Eric Trump in Tokyo Metaplanet capital plan and BTC seasonality risk map
- Gemini IPO Valuation math and what a 17 to 19 range implies for proceeds