


Executive summary
Nemo Protocol on Sui faced an exploit that moved about two point four million in stablecoins. The team paused risky components and began a review. As a result users want clarity on scope, next steps and recovery options. This version explains what happened, why it matters and what to do now.
What happened
During a short window attackers triggered a sequence of calls that touched stablecoin balances. First funds split across several addresses. Then transfers converged again. Finally the flow attempted exits through venues that accept stable assets. Because the pattern escalated fast the team focused on containment and evidence preservation.
Impact at a glance
Estimated loss near two point four million in stablecoins
Several functions paused while audits proceed
Tracing active across fresh wallets and routers
User deposits discouraged until the safe list returns
Why it matters
Clear rules for pausing and unfreezing protect users. However broad freezes can trap healthy balances. Therefore projects need simple playbooks that explain triggers, review steps and unlock timing. Moreover investors judge credibility by how transparent the team is during the first days after an incident.
Likely root cause angles
Chained call path that original tests did not cover
External state drift that allowed a brief mispricing
Approval reuse that surprised the signer
Cross chain exits that fragmented the audit trail
Threat model snapshot
Signal Relative weight Comment
Burst of contract calls High Many calls to a single function in a short window
Unusual stable deltas High Large moves between pools without matching flow back
Fresh aggregator addresses Medium New routers touching core pools for the first time
Price slippage outside band Medium Quotes stray beyond usual tolerance for stable pairs
Small multi hop exits Medium Many small transfers toward new addresses
What users should do now
First confirm approvals and revoke any that you do not need. Next export balances and recent receipts. Then wait for the safe list of contracts before sending new funds. If you must interact use a very small test and save screenshots. Finally keep a short record in case the project opens claims.
Defense playbook for teams
Publish a short policy that defines triggers scope review and appeal windows
Release hashed snapshots of any block lists with timestamps
Share reason codes for each address on the list
Coordinate with venues and bridges so that removals propagate quickly
Run dry runs for disclosure and set a cadence for updates
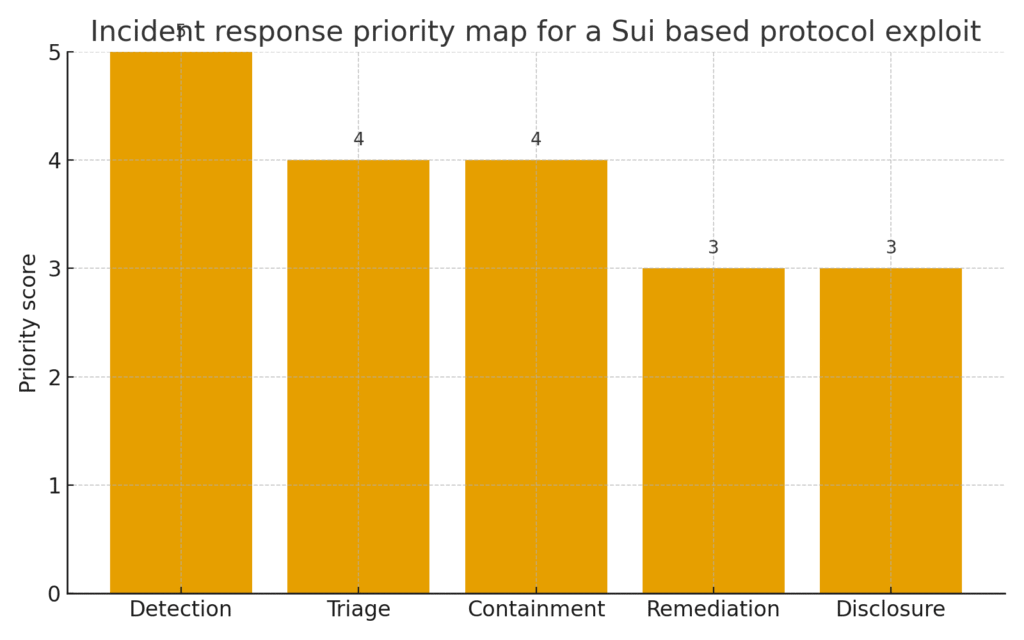
Figure 1. Incident response priority map
Incident response map
Detection
Set alerts for function frequency gas usage spikes and slippage outliers.
Triage
Validate the alert with real transfers and a simple timeline.
Containment
Pause affected components where contracts allow it. Notify venues.
Remediation
Patch code where possible and document tests that cover the path.
Disclosure
Publish plain updates with scope next steps and dates for review.
Outlook
Expect a quiet period while audits complete. Soon after a safe list should return. If the post mortem explains the root cause and the fix in clear language confidence can recover. Otherwise users will price higher risk until transparency improves.
Mini dataset on chain signals seen during the first window
| Signal | Relative weight | Comment |
|---|---|---|
| Burst of contract calls | High | Many calls to a single function in a short window |
| Unusual stable deltas | High | Large moves between pools without matching flow back |
| Fresh aggregator addresses | Medium | New routers touching core pools for the first time |
| Price slippage outside band | Medium | Quotes stray beyond usual tolerance for stable pairs |
| Small multi hop exits | Medium | Many small transfers toward new addresses |
Incident response map for readers
Detection
Watch alerts that track function frequency, gas usage spikes, and unusual slippage.
Triage
Validate the alert by checking real transfers and balances. Build a simple timeline.
Containment
Pause affected components where the contract allows it. Coordinate with venues.
Remediation
Patch contracts where possible and publish a plan for claims and unlocks.
Disclosure
Share plain language updates on scope, next steps, and dates for review.
Outlook and what to watch
Expect a short quiet period while the team reviews every touch point. Then look for a safe list that defines where users can move without risk. Finally, read the post mortem. A good document includes the root cause, the fix, the tests that now cover the path, and the plan for users who took losses. Clear writing builds trust faster than any slogan.